If your company operates its own website or web application, your operations team is likely dreading the moment error rates spike, or, worse, for the site to go down completely. HTTP errors can be incredibly disruptive for your business because they prevent customers from making purchases or using your product. This immediately impacts revenue and can also lead to a loss of trust. At worse, customers may end up switching to competing services or become critical on social media.
It’s important to get alerts when your site has a spike in HTTP errors so your team has immediate visibility. Resolving this issue quickly can minimize the impact on customer experience and revenue. Having the right tools in place can reduce your mean time to resolution (MTTR), pay off your investment quickly, and earn praise from your operations team, leading to more satisfied customers.
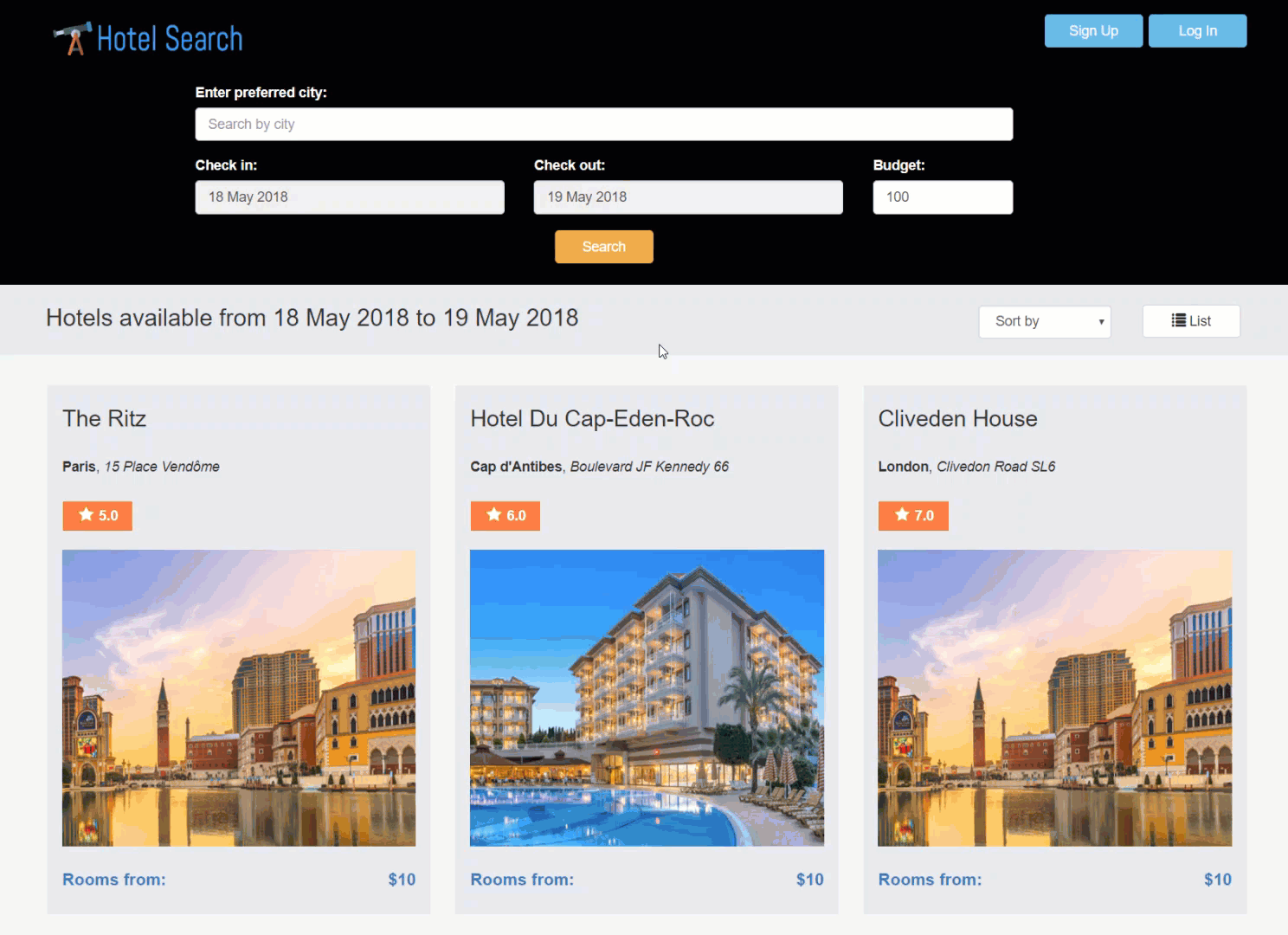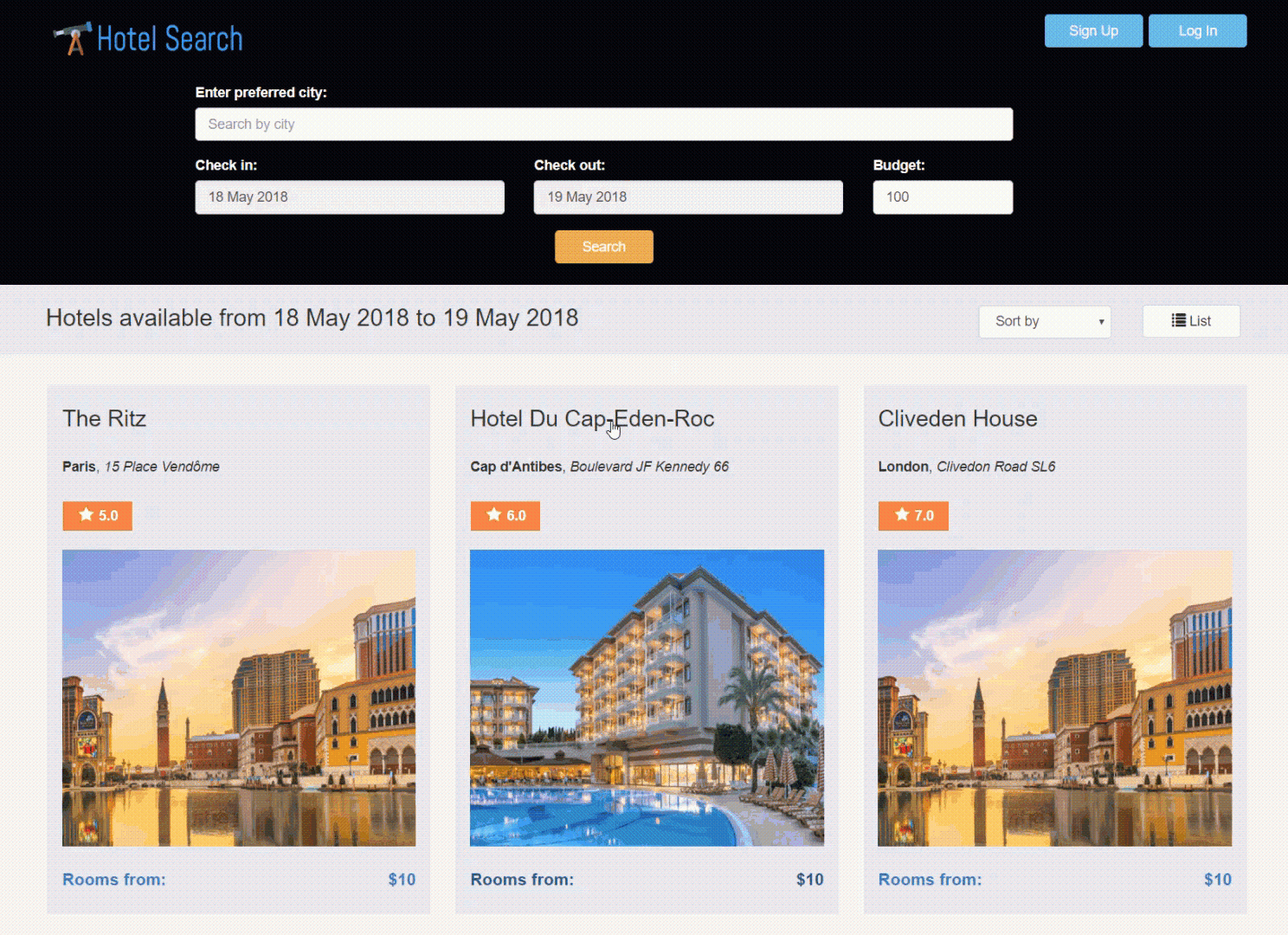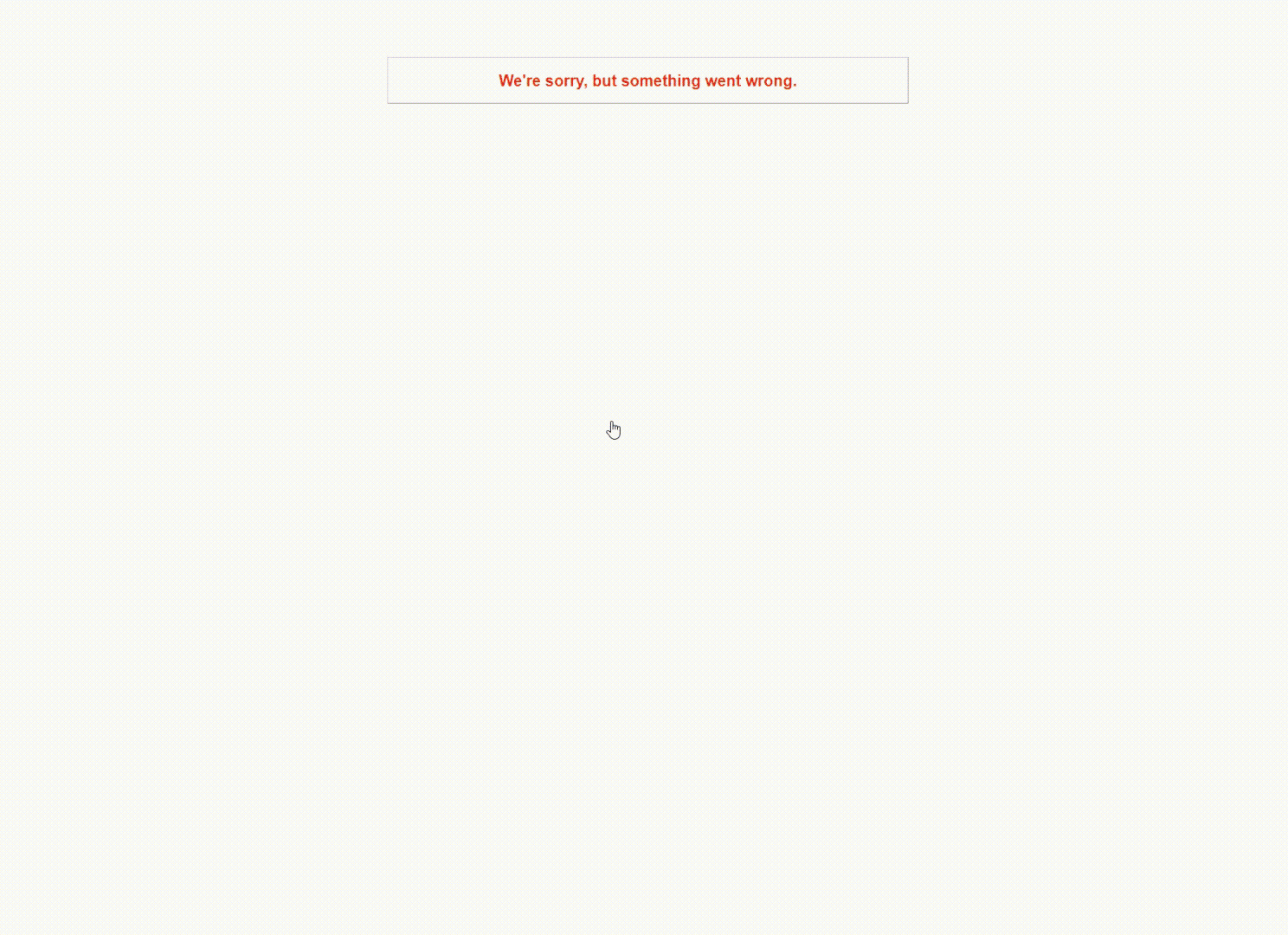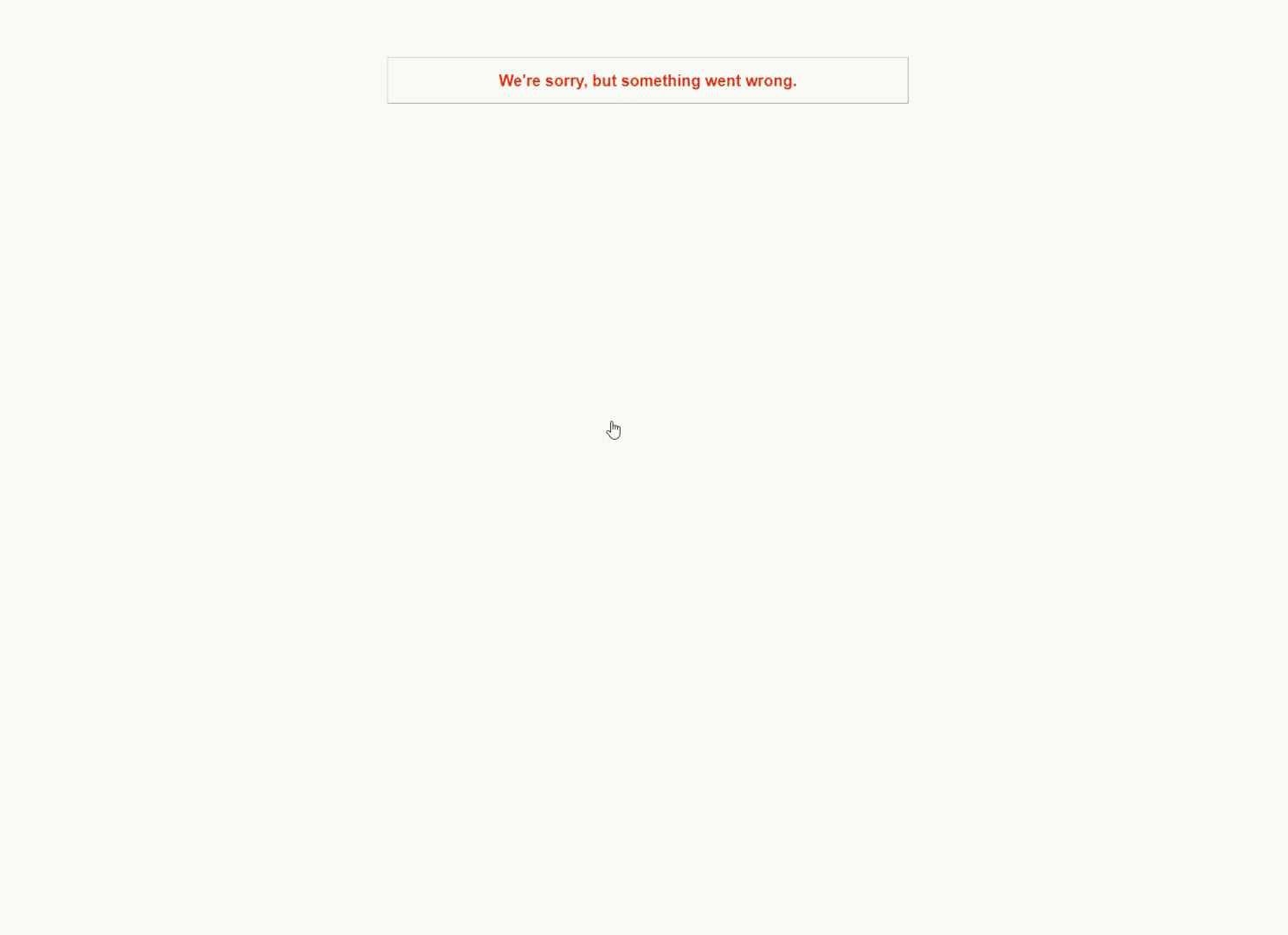
Let’s tour how an operations team troubleshoots a problem with an example scenario. We will troubleshoot a hotel search website problem that prevents customers from booking. When we click on one of the hotels, we get an error message saying, “We’re sorry, but something went wrong.” This could be caused by numerous problems on the back end: errors in the web application, the hosting infrastructure, the database, or more.
© 2013-2015 Docker, Inc. All rights reserved.
We’ll use the suite of SolarWinds® cloud monitoring tools to identify and fix the problem with this site. The Pingdom® solution will quickly notify us when the site has an outage. Through AppOptics™, the application performance monitoring (APM) tool, we’ll see which back-end service is responsible. Finally, we’ll use the log management features in Papertrail™ solution to determine the exact root cause.
Monitoring for HTTP errors
The most important part of delivering a highly available and reliable web service is having good website monitoring tools in place. Ideally, you’ll have an external service perform uptime and health checks. Therefore, if your service has an outage, an independent party can alert you immediately.
For over a decade, Pingdom has been a popular solution for availability checks. It can perform uptime checks according to a configurable time interval, and you can select different geographic locations around the world. Its alerting feature integrates with a variety of platforms, including Slack. When it detects an outage, we get an immediate Slack notification.
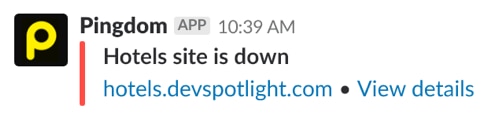
© 2018 Slack Corporation. All rights reserved.
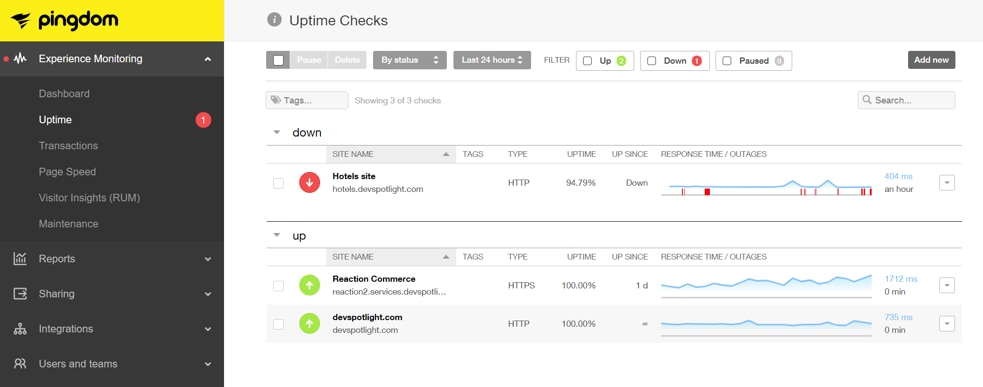
When we click the “View details” link, it takes us into the interface where we see that the “Hotels site” has turned red, indicating an outage. We can also see when the outage started. Additionally, this view shows us that none of our other sites has an outage, so it’s not something affecting our network connection or data center; instead, the error is something specifically affecting the hotel site.
To dive deeper into the cause of this problem, we switch to the APM solution called AppOptics. We see that there isn’t a problem with the response time on the website, so it’s not a performance issue. However, in the bottom left we see that the HTTP status codes have turned red.
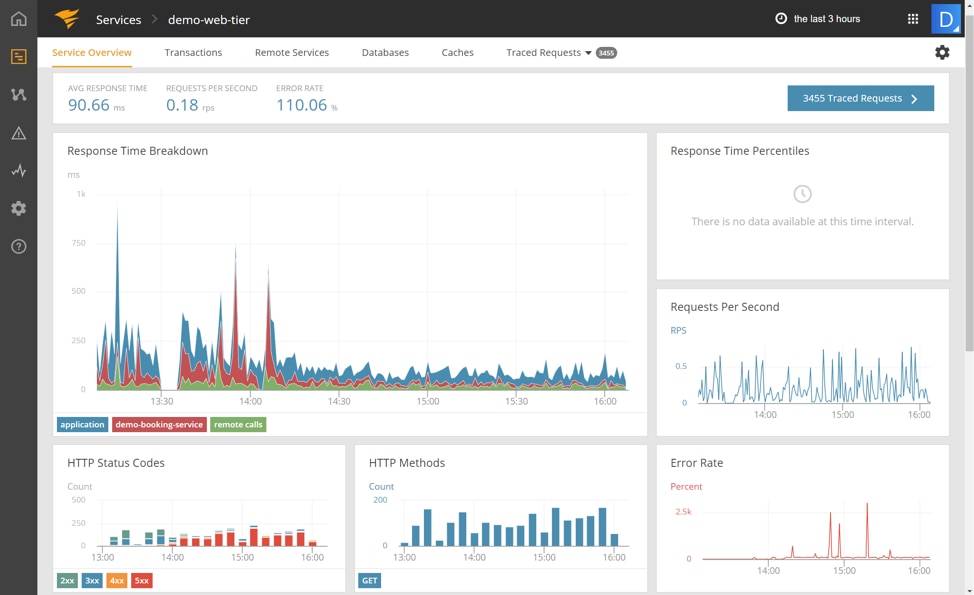
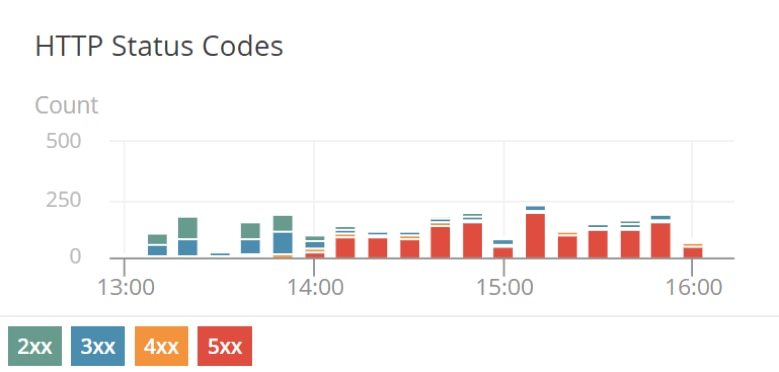
Let’s take a closer look at those status codes. Earlier in the day, AppOptics infrastructure monitoring was returning healthy codes, which were 2xx and 3xx, shown in green and blue. However, recently it switched to red, indicating HTTP 5xx errors. These are server errors, which means there is a problem with the web application server.
Finding the root cause
Next, we’re going to get more detail on one of these 5xx errors by clicking on traced requests. We click on the “Errored” filter at the top to show us the errors. Again, we can see they just started recently. We then click on a particular request to get the full trace.
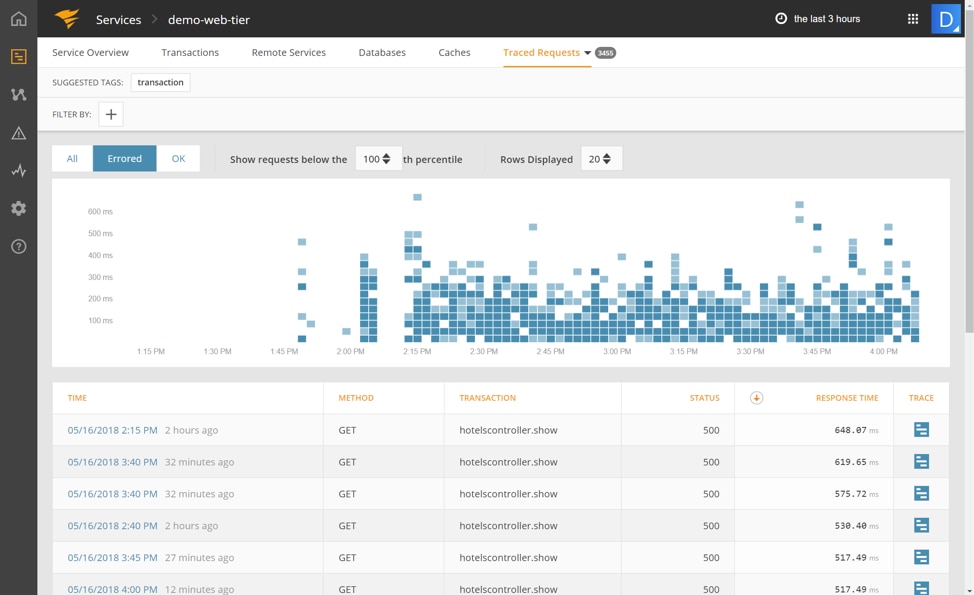
Next, we see the trace for one of these error requests along with an error message indicating the problem. It says, “Failed to open TCP connection to booking.neta-suites.com:8080 (getaddrinfo: Name or service not known).”
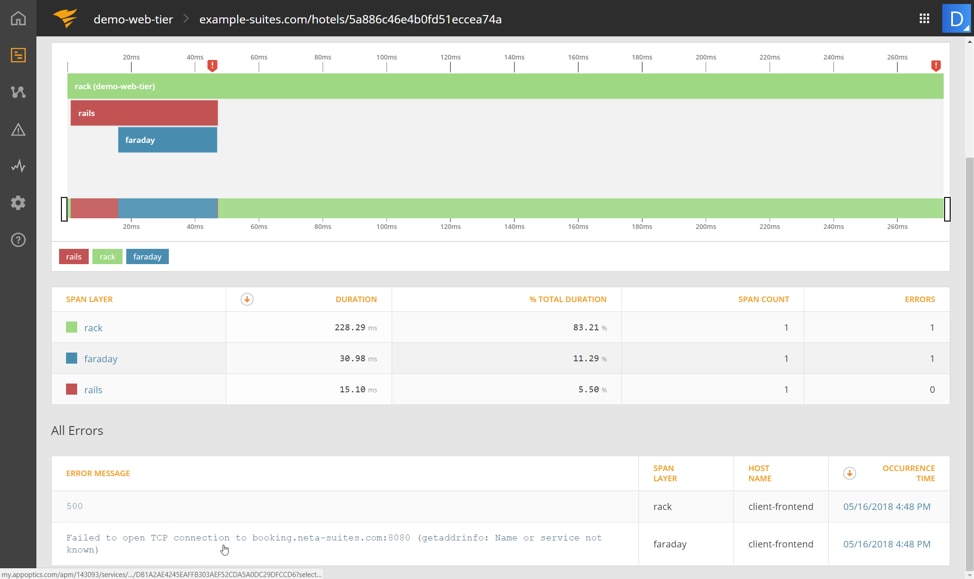
This indicates that our web application was trying to make a connection to a back-end service for booking. The booking service is essential for our hotel application because the website cannot accurately show hotel room availability without it. Since the domain name “booking.neta-suites.com” is not known, it could mean we have a missing entry in the domain name system (DNS). We need to understand why this service does not have a valid domain name, so let’s dig a little deeper. For that, we need to take a closer look at the logs.
Let’s switch over to the log management solution called Papertrail. It keeps a record of every log message created on the server. We’re actually running these applications inside Docker containers. Papertrail captures the logs from these containers as well. We’re able to filter on the host where this application is running to narrow down the set of logs.
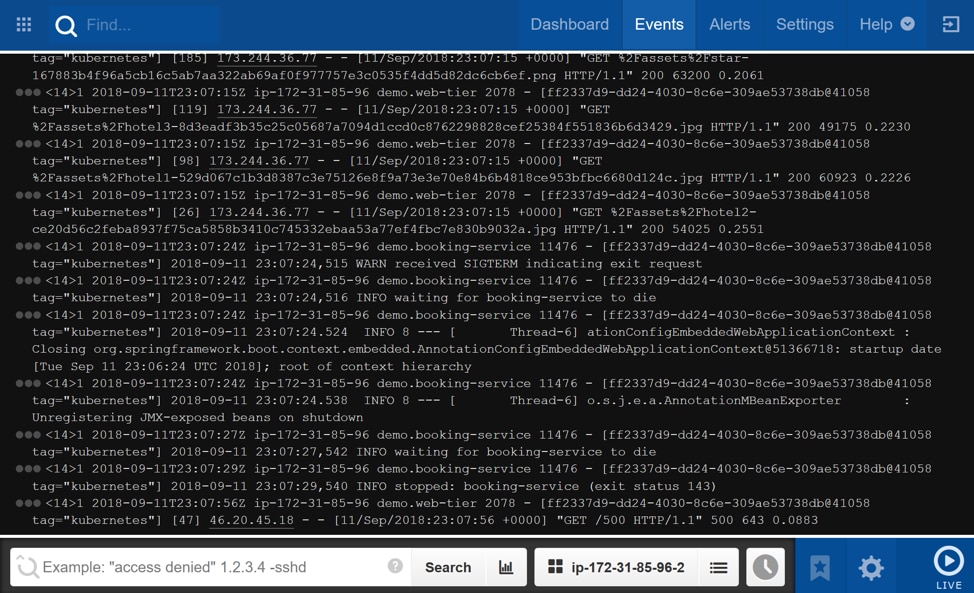
Looking closer at the log messages, we see that the booking service container received a SIGTERM signal indicating an exit request. This caused the booking service to “die” or stop running.

Finally, the big reveal: I’m the culprit who stopped the booking service container. I just happen to be a malicious administrator with a penchant for chaos! The solution to fix this problem is to start the container again.

PuTTY © 1997-2018 Simon Tatham
Containers can stop running for a variety of reasons beyond a malicious or careless administrator. A node could have failed, along with all the containers running on it. There could have been a change in the networking layer, such as in the Elastic Load Balancer. There could have also been a change on the physical host, such as disk space running out. It could have also just been due to the code deployment with a breaking code change. We’ll leave those examples for another blog. Regardless of the reason, having the right monitoring tools in place can help you find the root cause quickly.
Be proactive with alerts
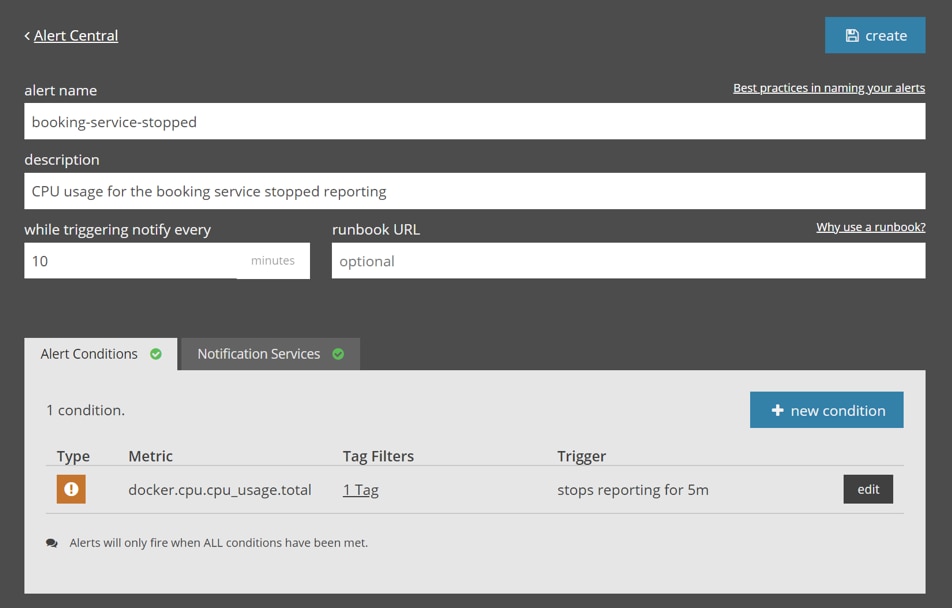
With better alerting, we can identify problems like this fast. In a production environment, the booking service should be running 100% of the time. Even during deployments, we should stagger multiple containers so there is never an outage. In that case, we can alert when no containers for this service are running. As a convenient proxy, we can trigger the alert on CPU usage being absent since a running container always uses CPU. When we get the alert for site outage, we’ll also get one for the container being stopped, which will guide us to the root cause faster.
Conclusion
A big increase in HTTP errors can indicate a big problem for your web service, and therefore for your customers. Using cloud monitoring tools like Pingdom, AppOptics, and Papertrail can alert you immediately when there is a critical problem. They can also help you identify the cause quickly and improve your mean time to resolution. Each of these tools offer invaluable services, no matter if you’re from a small company or a large one. They also give free trials, so set one up today and try it on your own web apps.
Sign up for the free trials today!